AI: How Google could improve its data centers
Early detection of failures
22 janv. 2023
Disclaimer: This informative article summarizes one of my projects. The article lacks major details in order to simplify the subject. It also lacks of discussion, and it is not recommended to use it for scientific purposes. As I don't work at Google, it is impossible for me to know if such algorithms are already applied or not.
You already know: when you run a program on your computer, it will either run successfully or crash.
In Google's datacenters, it's the same thing. A program run on their servers has a chance to succeed, but also a chance to fail.
And as this diagram illustrates, every job that ends in failure is a waste of CPU, RAM and electricity. And this can cost companies like Google a lot.

Detect failures before they happen
The idea of this project is to detect in advance for each job if it has a high chance of ending badly.
This work is based on the report "Learning from Failure Across Multiple Clusters: A Trace-Driven Approach to Understanding, Predicting, and Mitigating Job Terminations" written by N. El-Sayed, H. Zhu, and B. Schroeder, iSSN: 1063-6927, but with an updated version of the dataset.
Is it possible to detect a failure in advance? Let's try it!
The dataset
In 2019, Google released a dataset of approximately 7 TiB of execution traces from Google Borg, the resource manager used in Google servers. It gives us a lot of information, such as the events that occur for each program, the resources allocated, the final status of the program, etc.
We will try to use it with TensorFlow (an AI library from Google), using a very common classification algorithm: Random Forest.
Will it really work?
In fact, if we look more closely at the successes and failures, we can find different elements that differentiate them, and sometimes strongly. For example, when analyzing the planned CPU and RAM resources, we can see very different uses depending on their status.
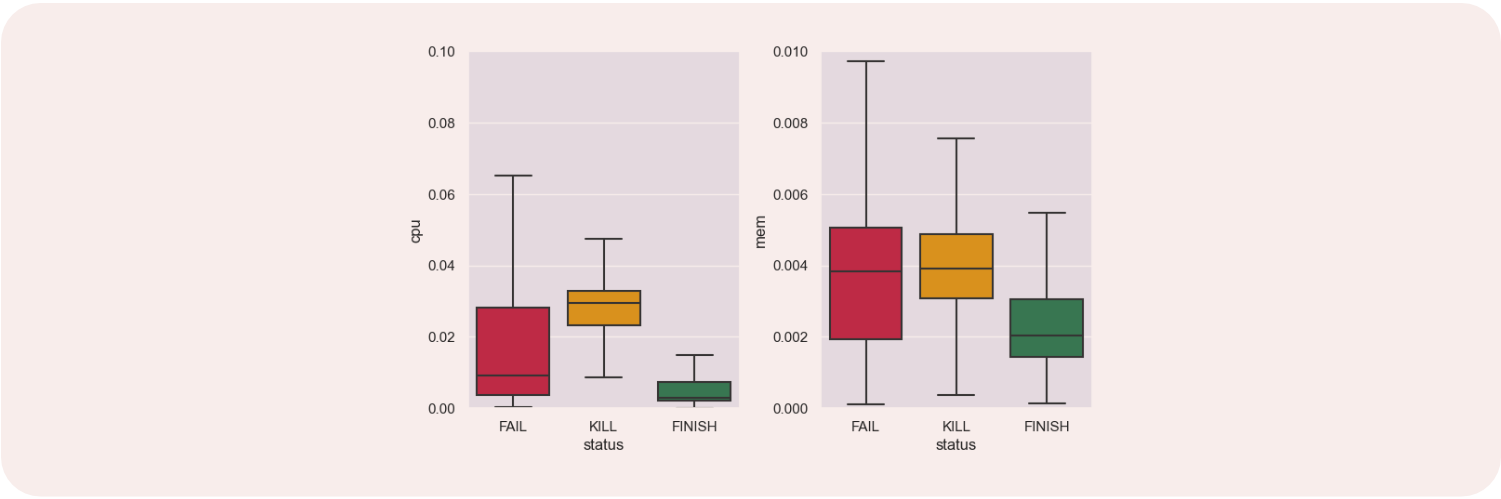
One can do the same work by looking at different attributes, and one will often find notable differences.
And then?
As a result, an AI may be able to detect whether a job is going to fail or not, even before it starts, based solely on this kind of data.
And indeed, this is the case: using a classification algorithm, we can predict in advance if a job will fail or not.
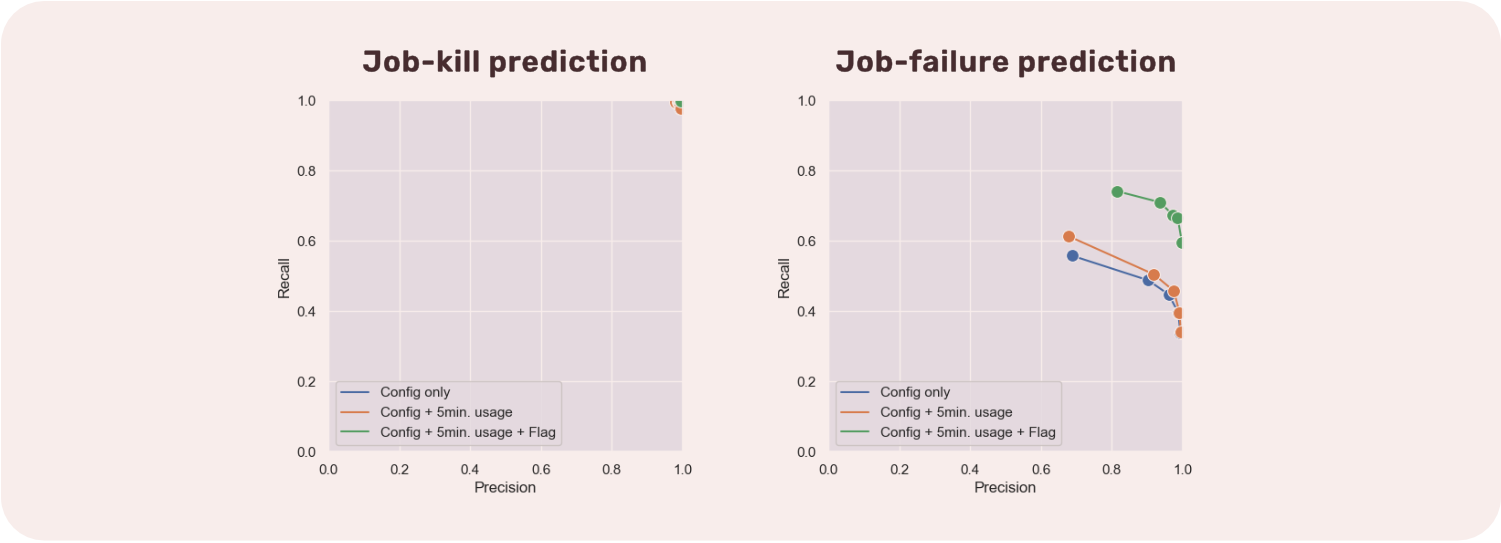
We realize that the predictions for job-kills are excellent. The predictions for job-failures are a little less good, but this shows that it is possible to do it, and with more knowledge in AI, it is surely possible to push the results further.
What do we do with this?
It is possible to do different things with these predictions. For example, it is possible to change the priorities of jobs, pause them, stop them earlier, duplicate them, etc.
Put together, by taking certain actions, it is possible to make very large resource savings on the scale of a giant like Google.